
Deep Learningにおける知識の蒸留
ここ数年のDeep Learningの発展は目覚ましく、急速に実用化が進んでいます。タスクによっては人間に匹敵する精度に達しているものもあり、システムの一部品としてデプロイする場面も増えてくると思います。そこで問題になるのが計算機資源の制約です。学習時には大量の学習データを用意し、GPUなどの計算資源で数時間や数日かかるような学習をしますが、推論時には限られたメモリや計算資源のもとで動作させる必要があります。リアルタイムに大量の入力データを捌く必要があったり、スマートフォンやエッジデバイスなどで動作させる場合には、この制約はさらに強くなります。
深くて大きいモデルの方が精度が出るが、実用を考えると軽量なモデルにする必要がある。こういった場面で最近よく使われる手法として、 知識の蒸留 (Knowledge Distillation) と呼ばれる方法があります。これは、(典型的には)大きくて複雑なニューラルネット(教師)の学んだ知識を蒸留し、小さくて軽量なモデル(生徒)の学習に利用するもので、単純に生徒モデルを学習するよりも良い精度を得ることが期待できます。最近、いろいろな場面でこの技術の適用を目にするので、基本的なアイデアの整理とその適用事例について、サーベイして情報をまとめました。
知識の蒸留 (Knowledge Distillation)
複数のモデルが学んだ知識を単一のモデルに移すというアイデアは既に2006年にModel Compression [1] として提案されていましたが、本記事では2015年の論文、Distilling the Knowledge in a Neural Network [2] を中心に、知識の蒸留の基本的な考え方や期待できる効果を整理していきたいと思います。
精度 vs 処理速度
Deep Learningでは一般に、深くてパラメータ数の多いモデルのほうが精度が上がりやすいことが知られています。また、単一のモデルで予測するよりも、複数モデルの予測結果を組み合わせる(アンサンブル)ほうが精度が上がることも知られています。精度 のみ が問題になる場面(例えば予測精度を競うコンペティション)では、こういったアプローチが採られます。
一方で、訓練したモデルをシステムに組み込んで動作させることを考えると、パラメータ数も少なく計算コストも小さい、軽量なモデルの方が適しています。
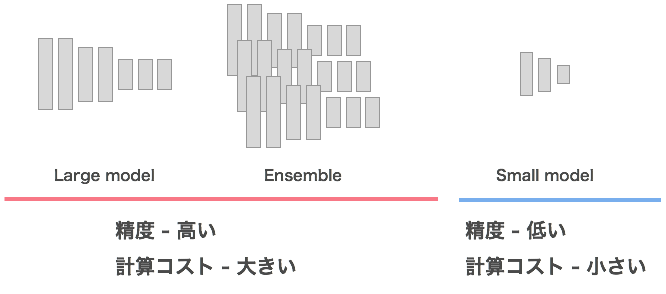
精度は高めたいがデプロイ時の計算機環境の制約であまり重たいモデルを使うことができない、、、というのが、よく遭遇する悩ましい状況だと思います。
基本となる考え方
このギャップを埋めるために、予測精度の良い、大きいモデルやアンサンブルさせたモデルを 教師モデル として準備しておき、その知識を軽量でデプロイしやすい 生徒モデル の学習に利用します。これにより、軽量でありながら教師モデルに匹敵する精度のモデルを得ることが期待できます。これが、本記事のテーマである「知識の蒸留」の基本的な考え方になります。
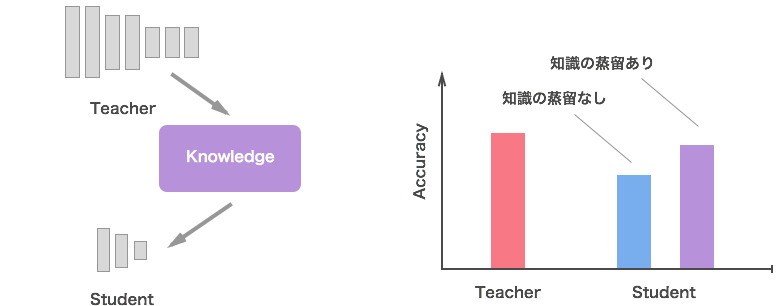
ここで、学習時と推論時に求められるモデルの役割を整理しておきます。
- 学習時:
- 大量の学習用データセットから構造化された知識を抽出する。
- 訓練データを丸暗記するのではなく、未知のデータに対する認識精度が良くなるように訓練を行う。
- 推論時:
- 限られた計算資源の中で動作する。
- 予測精度だけでなく、処理速度も重要となる。
通常の学習では学習と推論に同じモデルを利用しますが、知識の蒸留の枠組みでは、学習データから知識を構造化・一般化する部分は教師モデルが担当し、その知識を蒸留して推論に適した生徒モデルに継承させる、というように役割分担をする形となっています。
継承させたい「知識」について
最初に、学習データから得られる情報と、学習済みの教師モデルから得られる情報の違いについて考えてみます。画像分類タスクを例にすると、学習データは入力となる画像と正解クラス(図では「犬」)のペアになります。犬が正解ということはわかりますが、それ以外のクラスはどれも等しく「正解ではない」という情報しかありません。
一方、学習済みの教師モデルの出力は、合計すると1になる確率の形で、クラスごとのスコアとして出力されます。正解出ないクラスのうち、猫は惜しいけど車は全然惜しくない、といったことも、相対的なスコアから知ることができます。概念的に何と近いのか、どれとは全然違うのかといった情報を知ることができるため、学習データよりもより豊かな情報を伝えることができます。この粒度の細かい情報こそが、生徒モデルの学習に利用したい「重要な知識」となります。
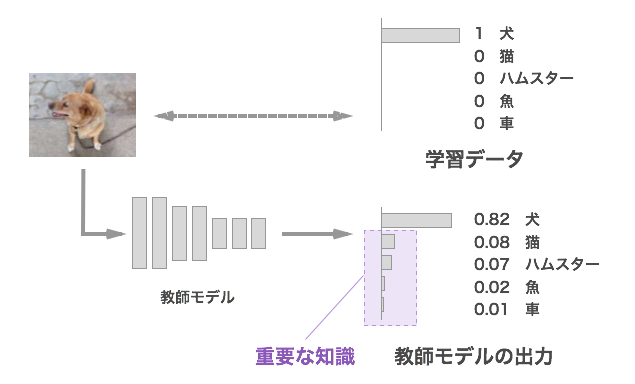
教師モデルの出力が重要な知識である理由について、もう少し掘り下げてみたいと思います。
通常のDeep Learningの学習では、学習データに対する損失が小さくなるように学習を進めますが、本来の目的は 未知のデータを正しく認識できること であるはずです。言い換えると、学習データを丸暗記するのではなく、汎用的に使える知識を獲得することが目的のはずです。私たちは「犬」というと「目があって耳があって足があって尻尾があって、、、」と思い浮かべることができますが、学習データは入力画像と「これは犬である」という情報のみで、そういった情報は得られません。
ですが、未知のデータに対しても良い認識精度を持つ教師モデルであれば、こういった知識を持っているはずです。学習を進める中で、「犬とは、、、」といった一般的な概念を獲得していることが期待できます。この学習済みの教師モデルの持つ、入力画像のどこに注目すればよいか、どのように構造化・一般化して認識するかといった知識が、学習データには含まれない重要な情報となるわけです。
教師モデルの出力であるスコアの分布にはこういった構造化された知識が反映されているはずなので、これを生徒モデルの学習に利用します。
生徒モデルの学習
ここでは、知識の蒸留を使って生徒モデルを学習させる方法について説明します。
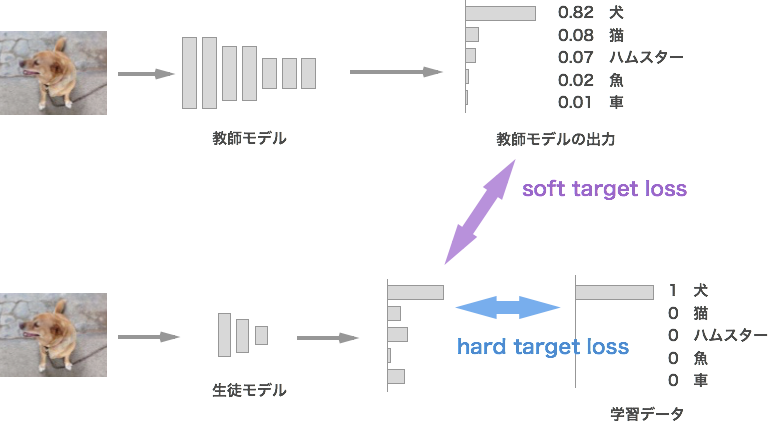
先ほど説明した通り、教師モデルの出力を学ぶべき「知識」として生徒モデルの学習に利用します。具体的には、教師の出力をソフトターゲットとして、生徒の出力の分布がこれと近くなるような損失(soft target loss)を学習に利用します。また、学習データが利用可能な場合は、通常通り学習データの正解ラベルをハードターゲットとしてクロスエントロピーなどの損失(hard target loss)を利用します。ラベルなしのデータを利用し、soft target lossのみで知識の蒸留を行うことも可能です。
まとめると、
- Soft target loss: 教師モデルの出力の分布と近くなるような損失
- Hard target loss: 学習データの正解ラベルを利用した通常の損失。使わないことも可能。
(どうでもいいですが、supervised learningを教師あり学習と訳すと非常に紛らわしいので、使うのをやめました笑)
ちなみに図では教師は単一のモデルですが、複数の教師の出力の平均を取ることも多いです。
期待できる効果
知識の蒸留によって期待できる効果をいくつか挙げます。
- 精度の向上:
- 知識の蒸留なしで通常の学習を行った場合と比べ、高い精度が期待できます。教師モデルに匹敵する精度や、場合によっては教師を超えるような精度も報告 [4] [12] されています。
- 正則化効果:
- 知識の蒸留でソフトターゲットを加えると強い正則化効果があることも報告されています。 [2] では、トレーニングデータの3%のみをつかって学習を行ったところ、知識の蒸留なしでは過学習(早期停止が必要)してしまうところを、知識の蒸留ありではきちんと収束したと報告されています。
- 膨大な知識を学ぶ:
- 単一のモデルで学習に時間のかかるような、クラス数が非常に多い&膨大な学習データがあるようなケースでも、問題を分割して複数の教師モデル(スペシャリスト)を学習させておき、それらの知識を利用することで、効率的に学習することが可能です [2] [9] 。
具体的な手法
先ほどはざっくりとした概念で説明しましたが、教師モデルを使って生徒モデルを訓練する方法にはいくつもバリエーションがあります。代表的なものについてまとめてみます。
出力を利用する方法
教師モデルの出力を利用する方法ですが、いくつかバリエーションがあります。まず、出力に近い層の変数の名前を決めておきます。
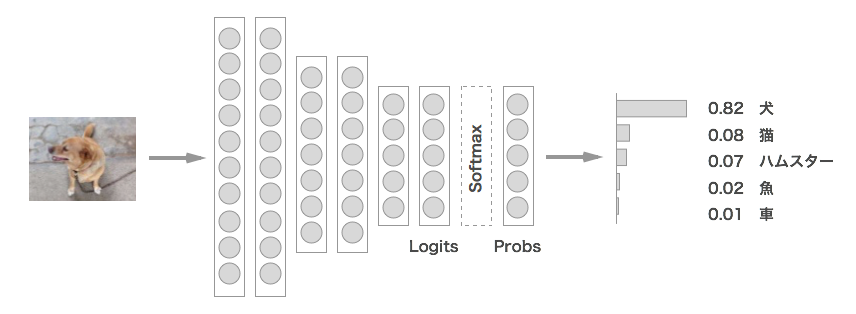
- Softmaxに入力する手前の変数をLogits
- Softmax入力後の合計して1になる変数をProbs
- 教師モデルのLogitsを \(v\) 、Probsを \(p\)
- 生徒モデルのLogitsを \(z\) 、Probsを \(q\)
とします。生徒モデルの出力分布が教師モデルと近くなるようにするための損失(soft target loss)は、以下のようなものが使用されます。
L2 Loss
一番シンプルな方法として、Logitsの差分のL2ノルムの最小化があります。 [3] などで使われています。
Softmax with Temperature
[2] で提案されている温度付きのソフトマックス関数を使う方法です。教師と生徒の出力について、ソフトマックス関数を使う代わりに、Logitsを温度パラメータ \(T\) で割った値を入力とした温度付きのソフトマックスを提案しています。これを、教師モデルと生徒モデルのそれぞれに適用します。
あとは、生徒と教師の温度付きソフトマックスの出力に対してクロスエントロピーを取って損失を計算します。
なお、温度付きソフトマックスを使うのはsoft target lossを記載した部分のみで、hard target lossや推論時はT=1として、通常のソフトマックス関数とします。
Note
温度付きのソフトマックスは、温度パラメータ \(T\) を大きくすると出力の分布がよりソフトになります。これにより、知識の蒸留のソフトターゲットで効率良く情報を伝達できるようになります。
なお、温度付きソフトマックスを使うとソフトターゲットの勾配の強さが \(\frac { 1 }{ { T }^{ 2 } }\) となることから、ハードターゲットを加える場合はソフトターゲットの損失に \({ T }^{ 2 }\) を乗じる必要があります。
KL Divergence
教師と生徒の出力の分布間の損失としてKL Divergenceを利用する方法です。教師の出力の分布pと生徒の出力の分布qが一致した時にゼロとなる指標なので、より自然な表現と言えます。 [3] で比較対象として言及されているほか、[10] 、[12] 、[13] でも使われています。
これにはKL(p||q)とKL(q||p)と2通りの方法があります。一つ目は以下の式となり、[3] や [13] はこちらのパターンです。教師の重みを固定して考えると(つまりpを定数と見ると)、これはクロスエントロピーの最適化と同じになります。
もう一つは以下で、こちらは [10] で使用されています。こちらの形式ではクロスエントロピーに加えて生徒モデルの出力分布のエントロピーを増やす方向に働きます。
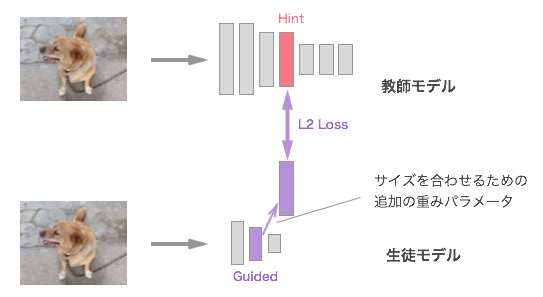
中間層の情報を利用する方法
教師の出力だけでなく、中間層の情報を利用する方法です。教師モデルの中間層をヒントとして生徒モデルの学習に利用する方法は [4] で提案されており、 [8] でも使われています。通常、教師の方が大きいモデルで隠れ層のユニット数が多いため、サイズを合わせるための追加の重みを間に噛ませる形になっています。なお、中間層の情報のみで知識の蒸留を行うというよりも、出力層での知識の蒸留に追加する形で利用されています。
また、[5] では、教師モデルの注意マップ(Attention Map)を生徒モデルが真似するというアプローチを取っています。教師がどこに注目して判断しているかの情報を利用するため、直感的にも良さそうに思えます。
適用事例
最後に、知識の蒸留の様々な利用方法を、一言コメントを添えてまとめてみます。
超軽量な表情認識エンジンをつくる
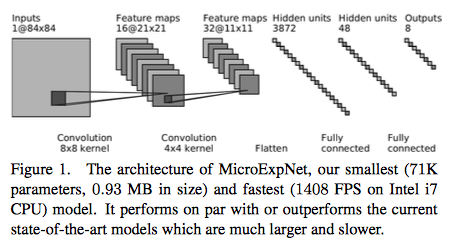
MicroExpNet: An Extremely Small and Fast Model For Expression Recognition From Frontal Face Images [7]
表情認識タスク向けに、知識の蒸留技術を利用して超軽量・高速なCNNを構築しています。知識の蒸留で軽量モデルを構築する実例として参考になりそうです。
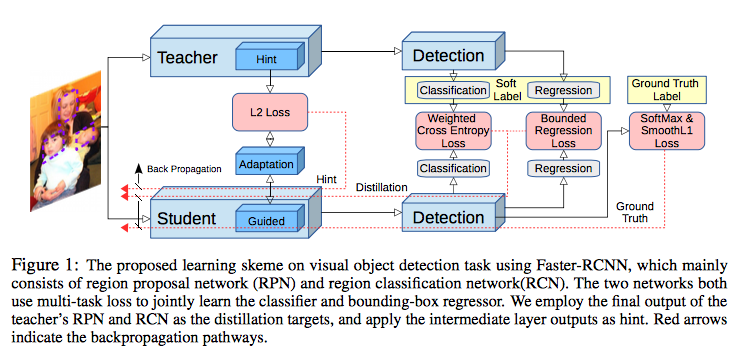
物体検出タスクへの適用
Learning Efficient Object Detection Models with Knowledge Distillation [8]
この論文では、物体検出タスクへ知識の蒸留を適用しています。Faster RCNNをベースに、教師の予測結果(ボックス位置、クラス)をソフトターゲットとして知識の蒸留をしているほか、中間層の情報をヒント [4] として利用しています。知識の蒸留の枠組みを使い、精度-速度のトレードオフを改善。
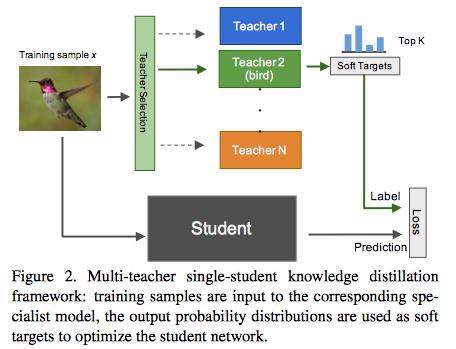
100,000クラスの分類器を学習する
Knowledge Concentration: Learning 100K Object Classifiers in a Single CNN [9]
知識の蒸留の枠組みを利用して、約100,000クラスという超多クラスの分類モデルを訓練する取り組みです。車や鳥といった大分類ごとに教師であるスペシャリストモデルを訓練しておき、複数のスペシャリストからの知識の蒸留という形で、100Kクラスの分類モデルを訓練しています。
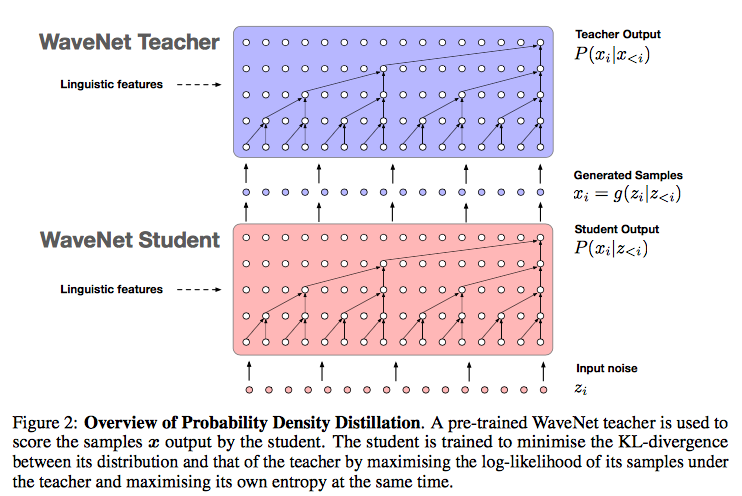
並列処理可能なWaveNet
Parallel WaveNet: Fast High-Fidelity Speech Synthesis [10]
リアルな音声の合成が可能なWaveNetですが、音声データをシーケンシャルに生成する(過去の自身の生成結果を利用する)ため非常に時間がかかるという問題がありました。そこで、学習済みのWaveNetを教師として、(過去の生成結果ではなく)ノイズから音声データを生成できる生徒モデルを訓練することで、並列実行可能な音声合成モデルを構築したとのことです。
なお、この成果はすでにGoogle Assistantで使われており、知識の蒸留で実環境にデプロイできるモデルを構築した素晴らしい例になっています。
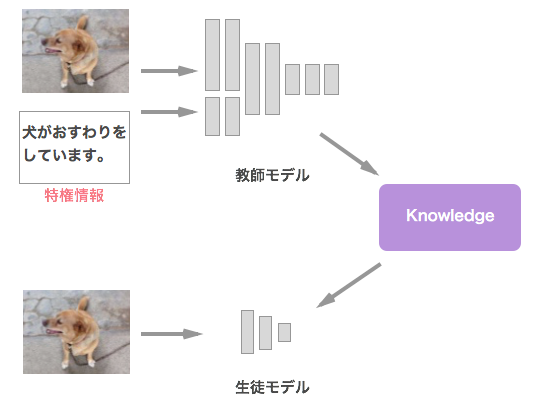
特権情報を使った行動検出
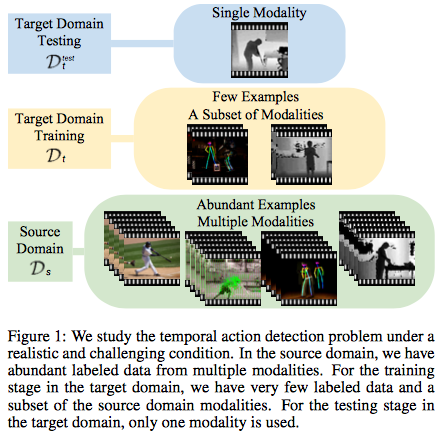
Graph Distillation for Action Detection with Privileged Information [11]
行動検出タスク向けに、特権情報を使った知識の蒸留を利用しています。推論時に受け取る入力データはRGB映像のみのモデルでも、知識の蒸留の枠組みを利用して、人のポーズやオプティカルフローといった入力をうまく学習に活かしています。
生まれ変わりで強くなる
Born Again Neural Networks [12]
この論文では、コンパクトなモデルを得るためではなく、より精度を向上させるために知識の蒸留を利用しています。具体的には、教師と生徒で同じモデル(あるいは同等のキャパシティのモデル)を使用したところ、教師を超える性能を示したとのこと。
その他
教師から学ぶのではなく生徒同士で教え合う
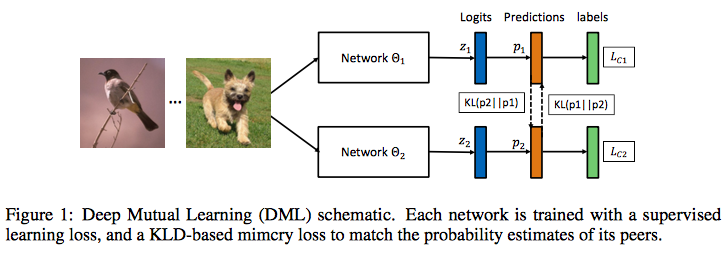
Deep Mutual Learning [13]
先に学習した教師から学ぶのではなく、複数の生徒同士が教えあいながら協力して学ぶというアプローチを取っています。CIFAR-100やPerson-ReIDタスクのMarket-1501データセットで実験を行い有効性を示しています。
複数の教師を使う代わりに、単一の教師で複数の変形を加えたデータを利用
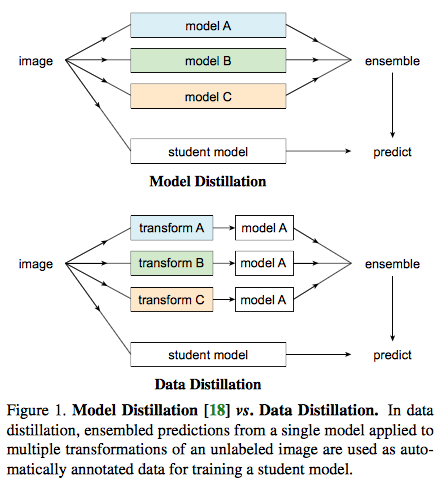
Data Distillation: Towards Omni-Supervised Learning [14]
複数の教師の出力を利用するのではなく、単一のモデルに複数の変形を加えたデータを入力することで複数の出力を得ます。これをインターネットなどで大量に入手できるラベルなしデータで実施することで、大量の学習データが利用可能になります。また、この論文では物体検出タスクやポーズ推定タスクを扱っており、通常の知識の蒸留で使われる教師の出力分布のソフトターゲットではなく、推論結果をハードターゲットとして(つまり普通の学習データセットと同じように)学習に使っています。
おわりに
調べ始めたらあれもこれもと増えていき、なかなかの長文になってしまいました。そして今更ですが、温度を調整して必要な情報に絞って抽出するので、「蒸留」という表現なんだなと気づきました。調べていくとまだまだ知識の蒸留の活用方法は出てくるのですが、イメージが伝わるくらいにはリストアップできた気がするのでこの辺りで。。。最後までお読みいただきありがとうございました。ではまた。
参考文献:
| [1] | Model Compression |
| [2] | (1, 2, 3, 4) Distilling the Knowledge in a Neural Network |
| [3] | (1, 2, 3) Do Deep Nets Really Need to be Deep? |
| [4] | (1, 2, 3) FitNets: Hints for Thin Deep Nets |
| [5] | Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer |
| [6] | Unifying Distillation and Privileged Information |
| [7] | MicroExpNet: An Extremely Small and Fast Model For Expression Recognition From Frontal Face Images |
| [8] | (1, 2) Learning Efficient Object Detection Models with Knowledge Distillation |
| [9] | (1, 2) Knowledge Concentration: Learning 100K Object Classifiers in a Single CNN |
| [10] | (1, 2, 3) Parallel WaveNet: Fast High-Fidelity Speech Synthesis |
| [11] | Graph Distillation for Action Detection with Privileged Information |
| [12] | (1, 2, 3) Born Again Neural Networks |
| [13] | (1, 2, 3) Deep Mutual Learning |
| [14] | Data Distillation: Towards Omni-Supervised Learning |