
CodexとBlenderによるライブステージのモデリング
Codex x Blenderで3DCGのモデリングがどれくらいできるか色々と試してみて、ある程度大規模な構造物がCodexのみ(人間は自然言語での指示のみ)で作れるようになったので、自分自身の振り返りを兼ねて取り組んだ内容をまとめます。最近はハーネスエンジニアリングという言葉をよく聞くようになりましたが、今後はAI Agentを組み込んだシステムを作り、意味のあるアウトプットの出せるソフトウェアを継続的に育てていく、ということがエンジニアの主戦場の一つになると思っていて、Agent主体で3DCGモデリングのできるシステムを作ってみよう、というのが今回のテーマです。作ったのは以下のライブステージのようなモデルで、CodexにBlender操作をしてもらいながら制作しました。最初は全然うまくいきませんでしたが、試行錯誤しながらやり方を改善した結果、最初に数回やり取りをした後は数時間自走し、大きなモデルを完成させることができるようになりした。この記事では、今回実施した内容や工夫したポイントの説明と、うまくいった例とうまくいかなかった例を含めて、具体的な試行錯誤のメモを書いています。少し長めですが、何かの参考になれば幸いです。

取り組みの背景
今年に入ってから「ハーネスエンジニアリング」という言葉をよく聞くようになりました。これは端的にいうと、長時間AI Agentが自律的に動作し成果を出すための、LLMの周辺の仕組みづくり、と理解しています。同じAIモデルを使っていてもハーネス次第で大きく精度が変わると報告されていて、今年に入ってから多くの記事を目にしました。モデル自体の精度も向上しており、ここ数ヶ月は特に、Coding Agentで大きめのタスクも安定してこなせるようになってきたと感じます。これもよく言われることですが、今後はエンジニアはコードを書くのではなく、作業主体はAgentに任せて、そのAgentが成果を出せるような仕組みを作って改善していくことが主戦場になっていくと思っています。このAgentが動きやすい仕組みづくりの実践として、AI Factory的なものを作ってみる、というのを、時間をとってやってみたかったのが、今回の取り組みのきっかけです。
あとは、仕事でComputer Vision関係を長年やっていたこともあり、Physical AI/ロボットの文脈でシミュレーション環境としての3DCG活用も面白そうとか、エンタメ領域での3DCGも興味があり、AI Factoryのプロトタイプのテーマとして、3DCGのモデリングを選びました。世の中でもMCP経由でBlender操作とかCAD操作といった取り組みを見かけるようになりましたが、ソフトウェア開発と比べるとまだCoding Agentにとっては歯応えのあるタスクであり、どれくらいのことがCoding Agent主体でできるのかを、実際自分で手を動かしてやってみたいなと。
そんなわけで、今回Agentが作業主体となって、3DCGのモデリングができるか、というテーマで色々実験をしてみました。取り組み内容や、うまくいったパターンでの工夫ポイントについてまとめますので、興味を持っていただけたらぜひ試してみてもらえると嬉しいです。3DCGはアウトプットが分かりやすく、綺麗なレンダリング結果が出てきたり、逆に全然ダメダメなアウトプットが出てきたり、やっていて楽しかったです。
CodexによるBlenderの操作
今回の取り組みでは、AgentとしてOpenAIのCodexを使用し、MacのローカルにインストールしたBlenderをCLIで呼び出し、Blenderスクリプト(Pythonコード)をBlenderコマンドに渡して、ヘッドレスで(GUIを立ち上げずに)シーン構築とレンダリングをする、というのを基本の使い方にしました。人(自分)とCodexは自然言語でやり取りをし、Codexがコード編集、コマンド呼び出し、画像読み取りを行いながら、指示したモデルの制作に取り組む、という形です。
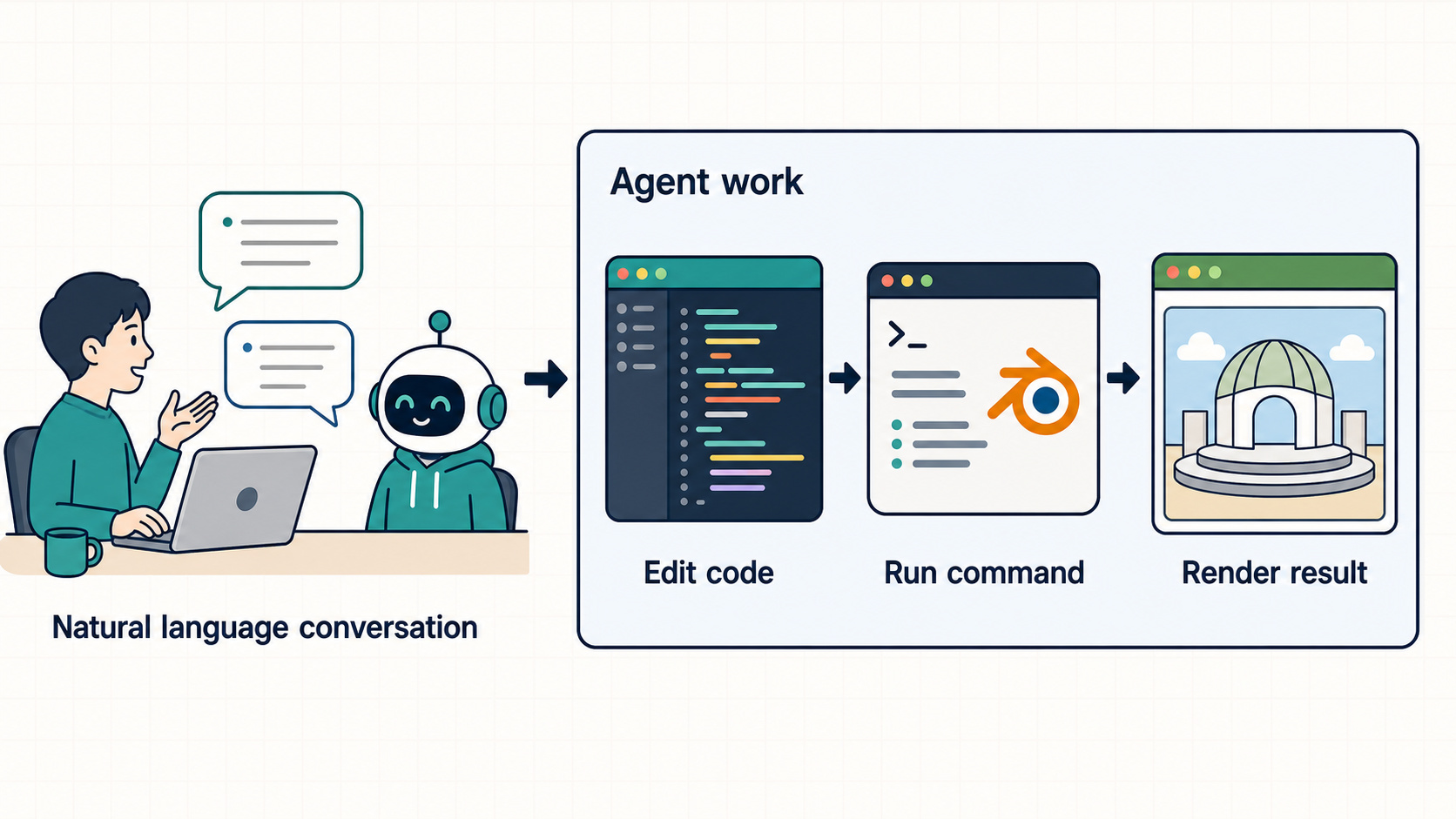
そのため、私はコードも書いていなければBlenderのGUI操作もしておらず、この記事中の3Dモデルは全部Codexがコードを書いて作ったものになります。(唯一例外でBlenderを触ったのは、完成品のモデルをみてみるのと、ついでに気に入った視点でスクリーンショットを保存するときだけでした)
このコード編集+コマンド実行のやり方を選んだ理由としては、
- コードとレンダリング結果が残るため活用しやすい(MCP経由で都度操作して完成しても再現が難しそう)
- うまくいったコードを部品化していけば、それらを組み合わせてより大きなモデルが作れるのではないか
- コード編集+コマンド呼び出しの形なら、Coding Agent(Claude CodeやCodex)と相性良いのではないか
といったあたりです。作業内容によって向き不向きはあるのだと思いますが、ある程度上手く動いたので悪い選択肢ではなかったと評価しています。
大規模な構造物を作るためのポイント
記事冒頭に完成例を載せましたが、色々と試行錯誤をした結果、大規模な構造物をCoding Agent主体で作ることに成功したので、うまくいったパターンで取り入れていた工夫について最初にまとめておきたいと思います。記事の最後にうまくいかなかった初期の例も載せているので、これらの工夫の有無での変化として見比べてもらえると嬉しいです。ポイントとしては以下の5点で、それぞれ詳しく説明していきます。
- 大きい問題を小さい問題に分解する
- 作業エージェント自身が成果物を確認できる
- 作業者とは別エージェントで品質評価をする
- 組み合わせやすい部品のインターフェースを決めておく
- ドメイン知識を埋め込む
1. 大きい問題を小さい問題に分解する
一番効果があった工夫としては、いきなり大きな構造物を作らせようとせず、小さい問題セットに分解してから取り組ませる、というものです。作って欲しいものを具体的に説明しつつ、それを完成させるために必要なパーツをAgentにリストアップしてもらい、それぞれのパーツをリアルな見た目にするためにさらに詳細な要件を整理してもらい、それをもとにパーツ単位で制作し、最後にそれらを組み上げる、というやり方に変えたところ、Agentの作成するモデルのクオリティが大きく改善しました。①番の具体的なイメージを伝える部分は人(私)が考え、②番目、③番目は指示を出して、エージェントに考えてもらっています。(今回は②や③の段階で特に修正指示とかもしていないので、具体化するフロー自体が効いたと思っています。)④、⑤についてはGOを出してあとはお任せでした。
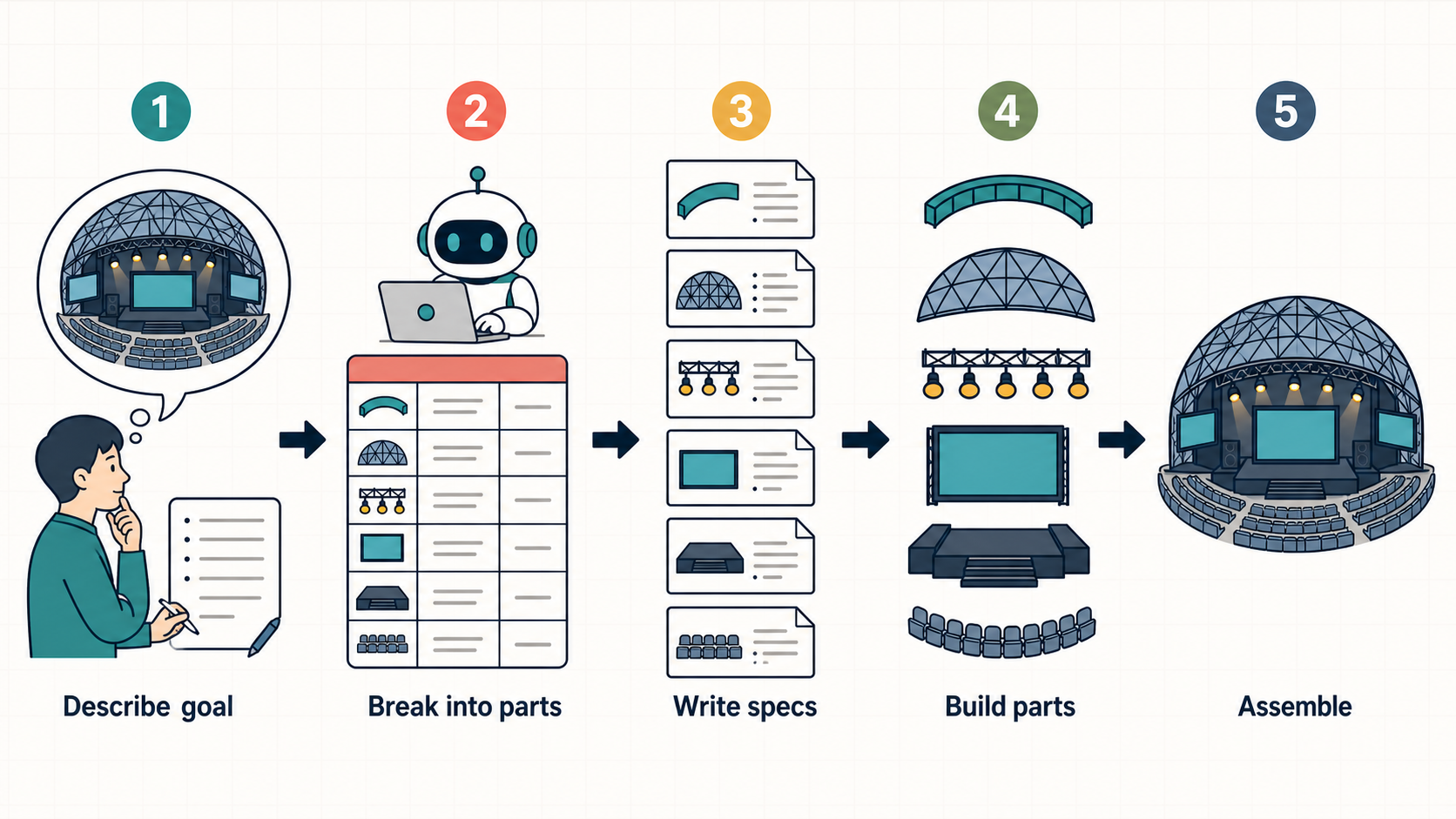
記事の最後に初期の試行錯誤の例を載せており、この「大きい問題を小さい問題に分解する」を取り入れる前の結果を残しているので、うまくいっている例と見比べてみてもらえると嬉しいです。素朴に「こういうものを作って」だけでは全然うまくいかず、具体的なイメージを伝えると多少改善はしますが、シンプルな形状を並べただけだったり、作って欲しいかっこいいディテールのモデルには程遠い状態でした。
あとは細かい工夫としては、部品に分解する段階で部品間の位置関係の整合性を取る方法も考えてもらうということと、部品ごとの詳細な要件を、部品単位でマークダウンファイルに保存しておく、ということが挙げられます。特に二点目についてですが、せっかく部品に分解して詳細を整理していても、それが作業を担当するエージェントに正確に伝わらないと結局しょぼいアウトプットになってしまう、ということがあり、作業の引き継ぎというか正確な指示出しの観点で、かならず部品ごとの仕様をまとめてもらうようにしました。
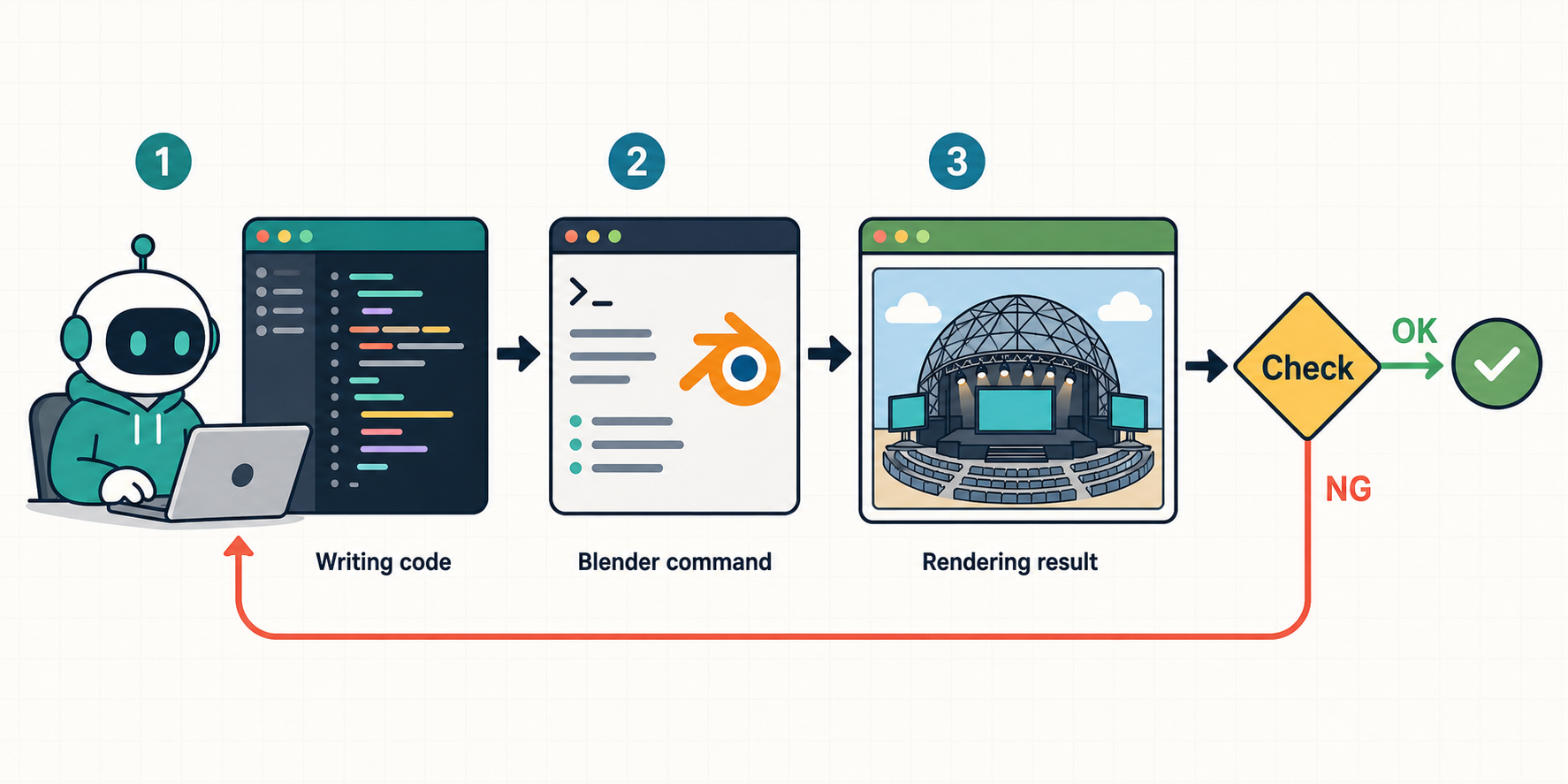
2. 作業エージェント自身が成果物を確認できる
エージェントの自律実行のためには基本的なことですが、作業するエージェント自身が、自身の作業がうまくいったかどうかを検証できるようにすることが大事です。Webアプリの開発であれば、ブラウザツールを使って実際に画面の確認や操作をしてみる、といったことが該当しますが、3DCGのモデリングのタスクではレンダリング結果の画像をエージェント自身が確認できることが大事です。まあそれはそうだよね、という話だとは思いますが、今回レンダリングまわりも処理を共通化して簡単にプレビュー画像を出力できるような仕組みも整備したので、各作業エージェントが安定して同じ構造で出力でき、作業そのものに注力できるようになったかなと思っています。
3. 作業者と別エージェントで品質評価をする
作業者エージェント自身に自己評価をさせると評価が甘くなりがち、ということもよく言われていて、評価を行うエージェントを別にするのが有効な手段です。今回は大きい問題を分解して、小さい問題ごとに作業エージェントを割り当て、作業が完了したら独立した評価エージェントに評価させて、OKなら完了、NGなら再度作業者エージェントが改善、という流れで作業しました。これにより、パッとみて明らかにうまくいっていない、みたいなケースは評価エージェントのレビューゲートほぼ解消され、人が毎回レビューせずに作業が進むようになりました。
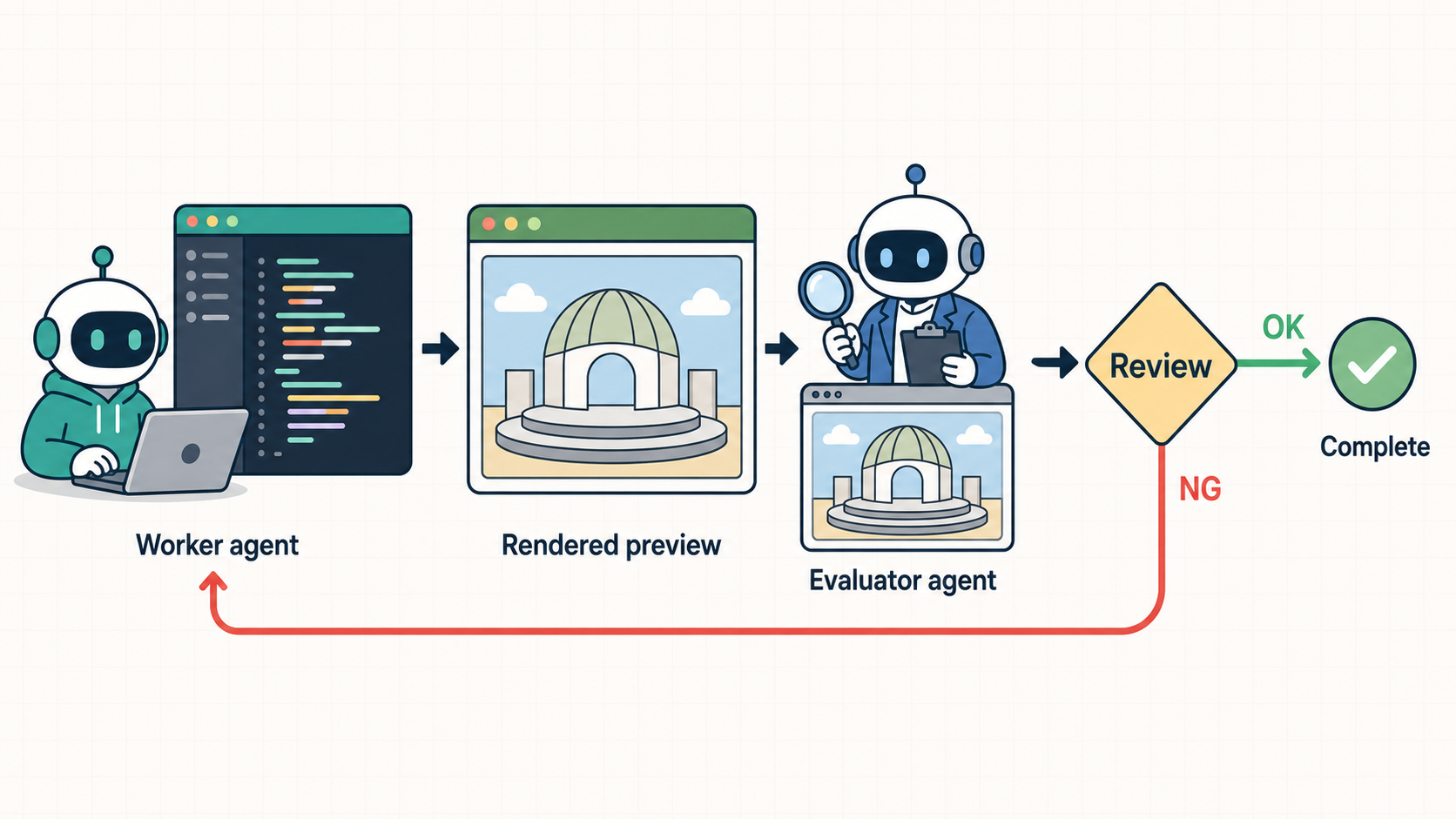
実際の進め方としては、全体の計画(大きい問題を小さい問題に分解の部分)をエージェントと対話しながら進めて、作業を進める段階になったら、作業用のサブエージェントと評価用のサブエージェントを起動して、もとの対話セッションはマネジメントをしてもらう形にしました。これにより、最初に人と対話した時の文脈を持った管理者が、小さい問題の作業を管理し、評価エージェントのOK/NGによってやり直しをさせる、次のタスクに進む、とかも仕切ってくれたので、最後の統合まで追加で指示を出すことなく完走できました。
評価エージェントについて、今はまだ「プロ品質になっているか評価して」のようなシンプルな指示だけですが、評価観点もきちんと言語化して、レビューの精度を上げると、まだ部品の品質を上げられるのではと思っています。
4. 組み合わせやすい部品のインターフェースを決めておく
小さな部品を組み合わせて大きな好俗物を作る上で、部品ごとにインターフェースがバラバラだと使う側がいちいち中身を確認しないといけなかったり、作った部品をリポジトリ内のどこに配置すればいいか迷って効率が落ちたり、見通しが悪くなるはず、と思っていたので、ものすごく単純な線引きですが、今回は以下のような方針で「Primitive」と「Module」という概念を定義し、共通言語として使うようにしました。
- Primitive
- 高品質なモジュールをつくるための基礎的な部品
- コンクリートのマテリアルや、モデルの構築で繰り返し使うメッシュの生成など
- Blenderのオブジェクトを返す関数として定義
- Module
- シーンの組み立てをする上で、意味を持ったある程度大きな粒度の部品。
- ステージのライト、大型ディスプレイ、ペンライト、座席など
- モジュールの組み合わせでより大きいモデルやシーンの組み立てができるようなもの
- __init__の引数でサイズや見た目を調整するパラメータを受け取るクラスとして実装
- 外からアニメーションのタイミングを挿入し、動きをつけられるような公開メソッドを持つ
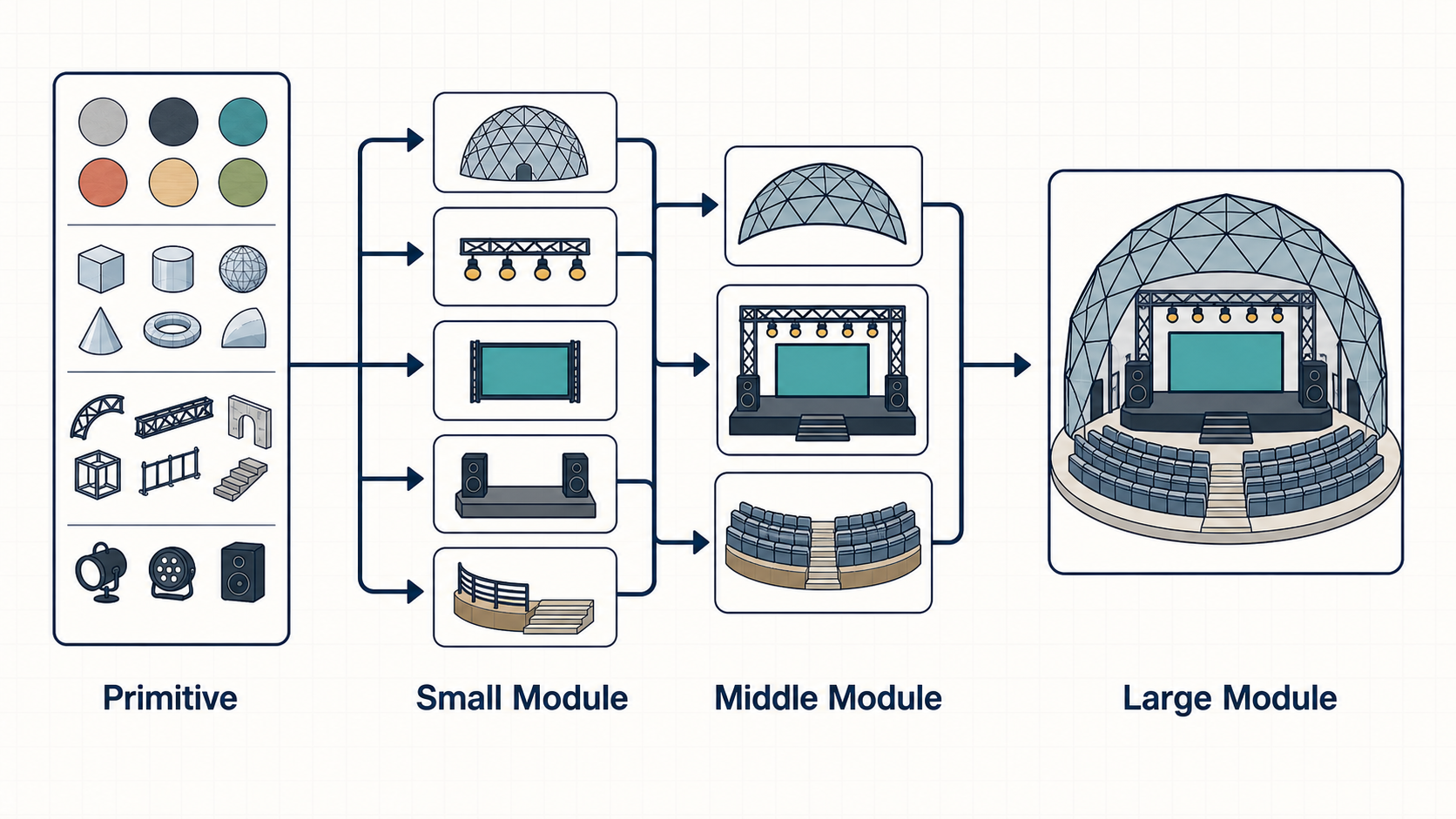
これらを設計や実装上の共通言語として、大きい問題を小さい問題に分解する際にも「どんなModuleやPrimitiveを組み合わせるとこれがつくれるか検討して」のような形で会話ができるので、意図が正確に伝わるし、検討段階と実装のギャップも小さくなるので、ある程度効果があったかなと思っています。
モジュールは「小さいモジュールを組み合わせて大きなモジュールをつくる」というようなイメージを持っていて、小さい部品単位でも再利用できるし、「ドーム」のような大きいモジュールも、それ自体さらに組み合わせてシーンを作れるので、今回「ドームとステージを組み合わせる」みたいなこともすんなりできたと思っています。設計時にイメージしていたのはPyTorchのnn.Moduleで、それ自体で機能を持つ部品を揃えていって、それらを組み合わせて大きい粒度の部品を作って、これの繰り返しで最終的なモデルをつくる、というようなものでした。
5. ドメイン知識を埋め込む
ドームやステージなどを作った時の最初のやり取りで、「ここはこういうやり方をすれば上手くいくはず」と、思いついたアイデアをエージェントに渡すようにしていました。例えば、例えば、ドームであれば部品間の位置の整合性は、単純なxyzの座標の値ではなく、円形ドームの中心からの半径や角度範囲使って記述するようにすると扱いやすいのでは、とか、巨大スクリーンの映像はShader Node使えばなんかいい感じの作れるんじゃないの?とかです。自分はBlender力は低い方でそれほど鋭い指示が出せたわけではないですが、伝えた内容はうまく拾って活用してくれていたので、きっとBlenderとか3DCGに詳しい人がこの仕組みを使うと、もっと洗練されたモデルができるのでは、と思っています。
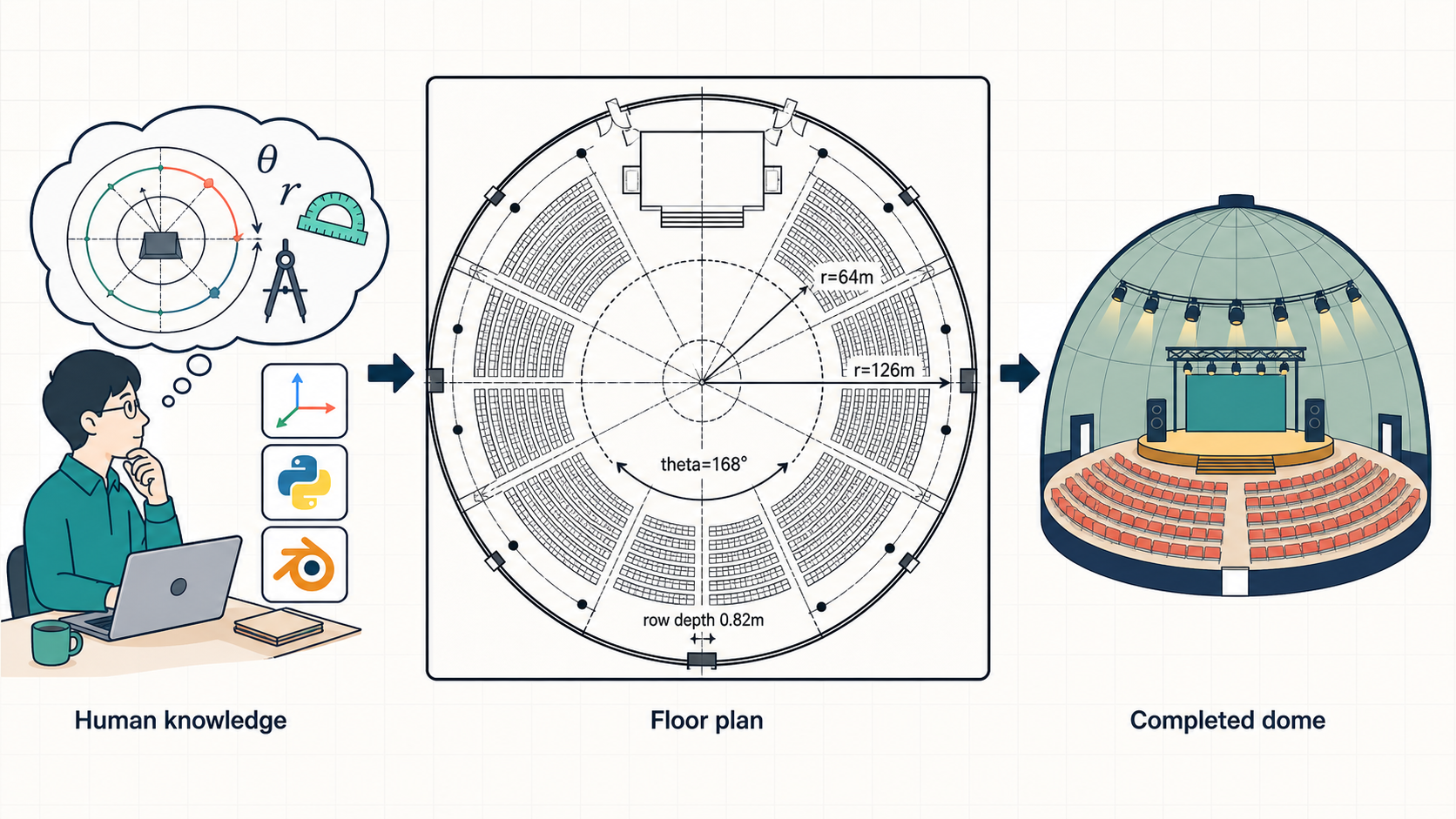
作業自体はエージェント主体で実行しつつ、人間側も貪欲に学んでいってドメインの解像度を上げていくのが大事なのだろうなと思っています。また時間を作ってBlender自体の勉強もしたいなと思っています。
うまくいった例
具体的な制作例として、まずは上手く行ったパターンの紹介です。
大型のドーム
音楽ライブの会場として使用できる、大型のドームを作ってもらった例です。具体的なイメージを伝えるために「野球用のドーム」と伝えていたので、ドーム単体では野球用のベースとかバックネットとかも作ってくれていますね。

「大きな問題を小さな問題に分解する」のところでも進め方に触れましたが、以下がやりとりの最初のメッセージです。(READMEにはプロジェクトの概要などが書かれていて、ここは自分で書きました。)含んで欲しい要素とか、Primitive/Moduleの粒度などを指示しています。
READMEを読んでこのプロジェクトの概要を理解してください。 ここでは、projects/detailed-domeプロジェクトをワークスペースとして、 リアルなドームのモジュールを作ることを目的とします。 以下を含む: ・野球用のドーム会場 ・野球をやるような中央スペース ・一階席 ・二階席 ・柱や壁や天井にも十分なディテールを検討 ・東京ドームの寸法を参考に十分な広さ Primitives/Modulesの例(一部): ・コンクリートのマテリアル(procedual ・階段状の円弧を段数、基準点(中心)、半径範囲、高さ範囲、角度範囲で指定して生成 ・椅子(Mesh共有 or Geometry Nodeで軽量に。ローポリで良いがスタジアムの椅子を意識。青色。) ・階段状の円弧の切れ目に出入り口 参考)実際のPrimitive/Moduleの開発例はprojects/proto-audienceを参考にしてください (他のプロジェクトはノイズになるので見ないで。) 以上の情報をもとに、まずはリアルで詳細なドームModuleを作成するために、 必要となるサブモジュールやPrimitiveの洗い出しと、空間的な整合性をコード記述で保つための、 各部品ごとに以下の情報を整理して欲しい。 ・サイズや位置の指定方法(中心点を基準にした半径範囲、高さ範囲、角度範囲などが良いとは思っている) ・リアルな見た目にするための工夫ポイント ・それをBlenderで実現する方法の考案(軽量化も視野に入れて。マテリアルは本物感を重視し、 そこも時間をかけていい。
で、いい感じの粒度で洗い出しをしてくれたので、「tasks/<title>.mdというファイルを部品単位で用意し、各部品ごとに、リアル化ポイントをもう一段具体化して、本当にリアルな見た目になる要件を具体的に記述し、その粒度であらためてBlender実装の方針を記述する、というのを、すべての部品について丁寧に検討してください。ここが品質の肝になると思うので、よろしくお願いします。」という指示を出して、部品ごとにさらに詳細を詰めてもらって、あとはマネージャー+作業者+評価者の組み合わせで、計画を立てていたセッションをそのままマネージャーにして進めてもらいました。時折コマンドの承認をしていた以外は、ここから先はお任せでした。
以下は作成された部品の一部です。こんな感じで、ドームを構成する部品ごとに作成してもらい、最後に組み上げてドームモデルが完成しました。

ペンライト
こちらは音楽ライブの観客のペンライトの配列を作ってもらった例。こちらは、配列の仕方(直線上or円弧状)や色などを指定できるようにして欲しいとか、4拍子で前後に振る動きにして欲しい、のようなリクエストをして作ってもらいました。まだ動きが機械っぽさがある気がしていて、自然な動きにするにはもう少し工夫が必要ですね。ドームよりもこちらを先に作っていたので、ドームの実装の際には参考実装としてこちらも見てもらうように指示していました。

ステージ
音楽ライブのステージ部分のモデルです。先に作っていたドームのモデルの寸法を参考に、ピッタリハマるように寸法を考えて作ってもらいました。ドームと同じように「大きなメインステージ、メインステージ後ろの巨大スクリーンと左右の大型スクリーン、ドームの中央でパフォーマンスするための円形のサブステージ・・・・」のように作って欲しい要素の列挙や、Primitive/Moduleの例(こういう粒度で部品化して欲しい)、などを伝えつつ、ドームの時と同じように部品の洗い出しと、すべての部品についての詳細ドキュメントを作ってもらってから動かしました。以下が作成された部品や完成したステージの一部です。こちらも、作業に入ってからはおまかせで完成させてくれました。

初期の試行錯誤
ここからは逆に、取り組みの初期の頃の試行錯誤についても参考で紹介したいと思います。
まずはやりたいことを端的に伝えてみる
VRoid Studioで作成したシンプルなモデルだけを渡して、あとはライブシーンのアニメーションを作りたい、というような単純な指示で作ってもらった例です。「シーンアセットの作成と、ライブシーンっぽい動きのアニメーション、照明のアニメーションやカメラの動きもつけて、短くて良いのでライブシーンを作成してください。」というように、いくつか要件は伝えたのですが、なんとも言い難い謎の映像が出来上がりました。

コンセプト画像を作ってそれの再現をお願いする
Codexで画像生成も使えるので、ライブシーンのコンセプト画像を作ってもらって、これを再現して、というような依頼の仕方を試してみました。独立した評価エージェントを立てて、画像を再現できているかを判定してもらい、OKがでるまで試行錯誤させる、というやり方もこの回から入れてもらいましたが、確かに回を追うごとにクオリティが上がっていることが確認できたので、その後の試行ではかならず独立した評価エージェントを立てるようになりました。見た目はだいぶいい感じになったものの、まだ全体的に平面っぽいなあ、というのが個人的な感想でした。

フロアプランを再現してもらう
次に試したのが、ライブシーンのコンセプト画像をさらにフロアプラン画像にしてもらい、それをインプットにモデルを作ってもらう、というやり方でした。今度は平面的ではなく、一応円形で空間的な配置もできるようになりました。ただ、依然として1つ1つのモデルはシンプルな図形の組み合わせという感じでした。
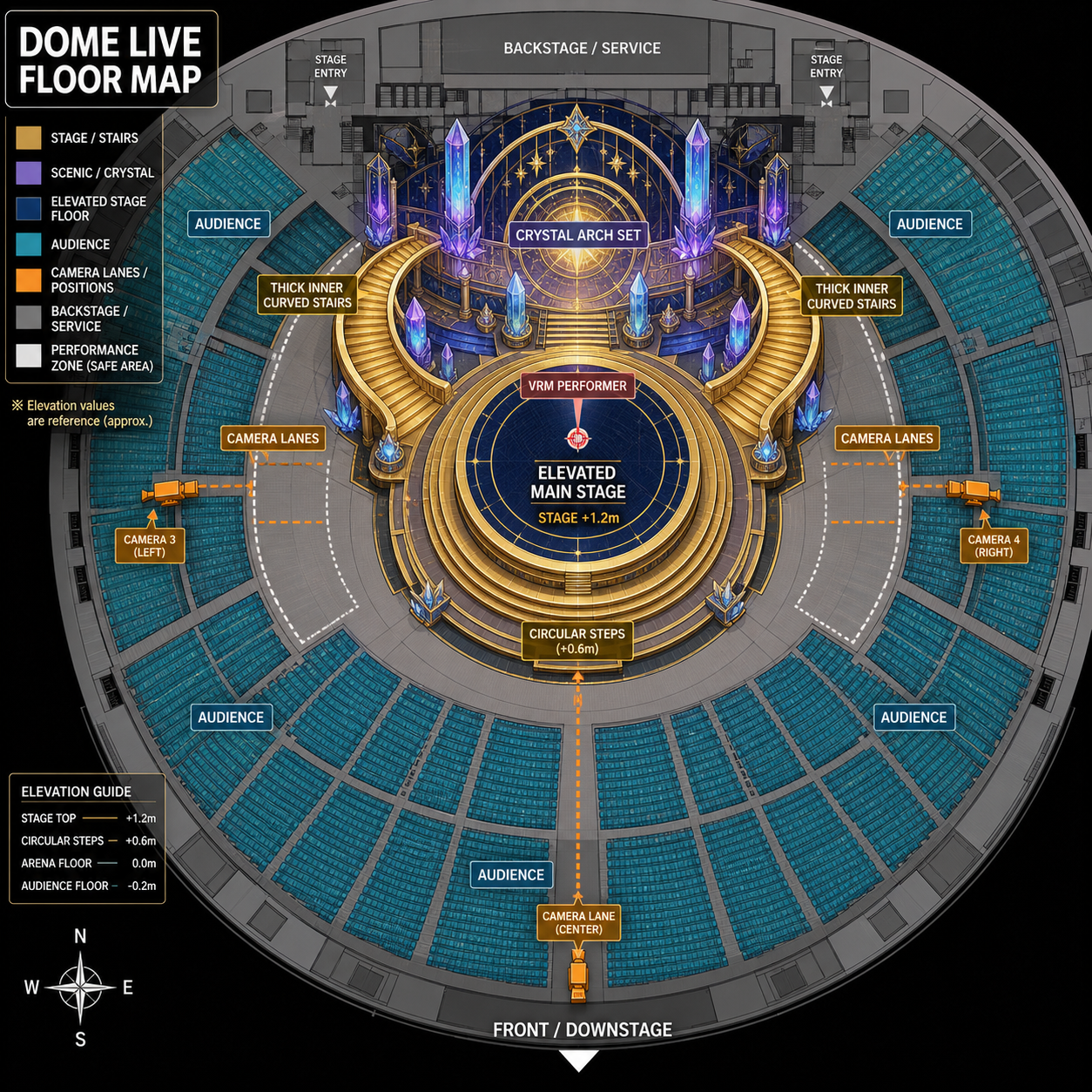

マテリアルや基本形状を部品化してそれを組み合わせる
音楽ライブとは別タスクで、部屋の家具のモデリングとかも少しトライしていて、この時に「ShapeやMaterialを組み合わせて10種類の高品質は机のバリエーションを作りたい。そのための計画を立ててください」というような、部品と完成品を同時に計画させる、というのを試しました。ここまでCodexで取り組んできたどのパターンよりも見た目がいい感じのモデルができていて、ちゃんと基礎部品に分解して組み合わせる、と段階を踏むと結構いい感じになるのでは?というのがここからの学びでした。

今後に向けて
今回、ある程度大きな構造物をCoding Agent主体で作れるようになりましたが、モデルのクオリティは正直まだまだだし、かっこいい映像が作れるようになって初めて価値があると言えるものだとも思っていて、まだまだやりたいことは沢山ある状態です。とはいえ、自力で作るのが難しいモデルが数日程度(指示出しの時間だけでみるともっと短い)で作れるようになってきていて、AI Factoryを作って育てることの強力さや面白さにも触れることができたので、ひとまずの区切りとしてブログにまとめました。
記事のテーマと少し外れるので触れませんでしたが、エージェントが大きな構造物を構築する過程で作成した部品(PrimitiveやModule)をカタログ表示するUIも作ったりしていて、数時間のエージェント実行でも途中経過が視覚的にわかりやすく、正しい方向に進んでいることが確認できたのでとても有用でした。AI Factoryをスケールアップしていくと多数のエージェントが同時並行でさまざまな作業を進める状態になるので、全体像の把握や問題箇所への介入のための人間向けのインターフェースも工夫の余地が大きいと感じています。カタログは眺めるだけでも楽しく、ついつい時間が経ってしまうので、「見る」だけで終わらずに次のアクションにつながるようなUIになると、改善ループがどんどん回るようにできるだろうなと。
また、改めてドメイン知識(今回であれば3DCGや映像制作)の強力さも体感したので、時間を見つけて関連分野の解像度を上げる活動を継続したいというのと、その道のプロがうまくAI Factoryを運用できるような仕組みが作れたら、遥かに高品質で魅力的な作品作りが、人とAIの双方の強みを活かしつつ進めていけるのだろうと思います。
ということで、Coding Agentを使った3DCGのモデリングについて、検証結果や考えたことについての共有でした。興味を持っていただけたらぜひお手元でもいろいろ実験してみていただけると嬉しいです。ではまた。